FleetLM
Context infra for LLM apps.
Context management is killing your costs. RAG + pub/sub + compaction + persistence = complexity that balloons fast.
FleetLM handles the full lifecycle: persist, replay, compact, deliver.
Write stateless REST. Deploy with docker compose. We handle state, ordering, replay.
The Context Complexity Trap
- Simple LLM calls → works great
- Add persistence → need database
- Multi-device sync → need pub/sub
- Context limits hit → need compaction
- Debug sessions → need event log
- Five systems. Distributed nightmare.
FleetLM does all of this out of the box.
What You Get
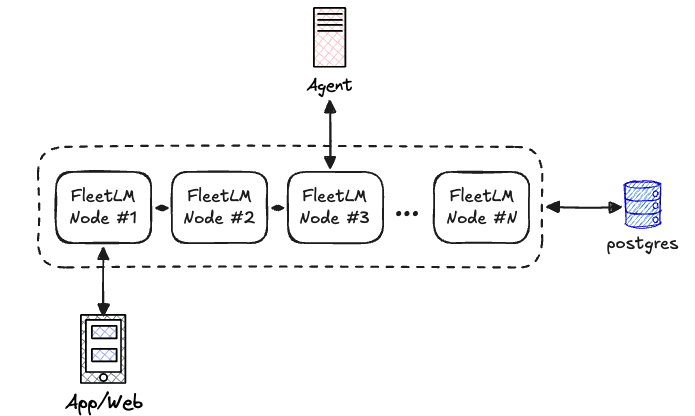
- Framework freedom – agents are plain webhooks, keep your stack (FastAPI, Express, Go)
- Durable ordering – Raft consensus, at-least-once delivery, zero data loss
- Real-time delivery – WebSockets stream every message, REST for polling
- Automatic failover – Raft leader election handles crashes (~150ms recovery)
- Horizontal scale – 256 Raft groups shard traffic across nodes
FleetLM makes LLM infra as boring as it should be. Run it once, stop thinking about gnarly chat infrastructure.
See Architecture for how Raft consensus, Presence, and Postgres work together.
Docs
- Quick Start – clone the repo, run Compose, send your first message.
- Agent Webhooks – payload schema, response format, registration knobs.
- Clients – REST endpoints and Phoenix Channel usage.
- Deployment – environment variables and scaling notes.
- Architecture – how FleetLM routes traffic, stores messages, and handles failover.